Solutions
Pick the problem you’re solving.
These pages are written for teams shipping production workflows: not demos, not vibes. Each section links to a dedicated “learn more” page.
Tenant isolation, stable contracts, and auditable artifacts so governance doesn’t collapse in production.
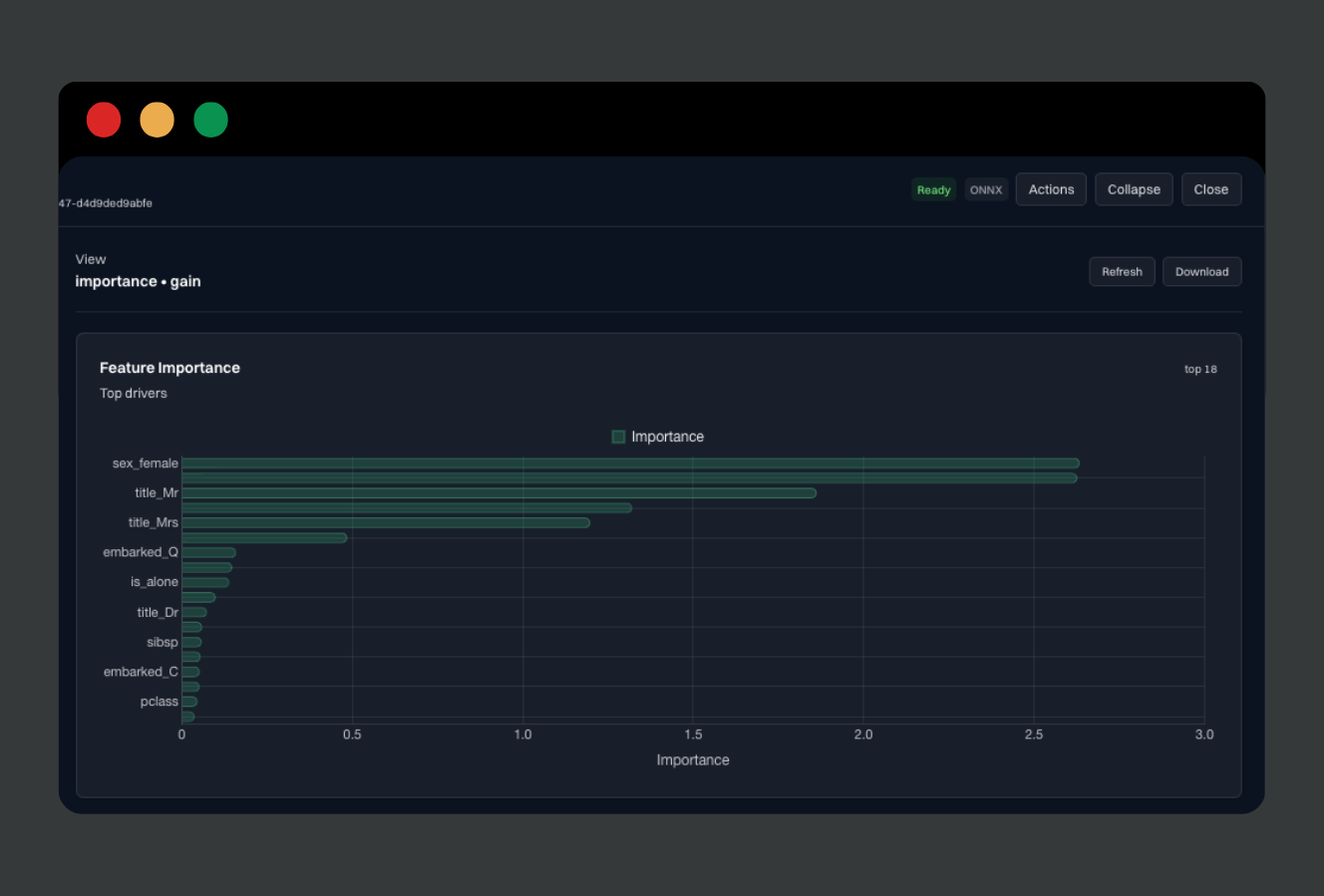
Build grounded copilots on your datasets: keep outputs traceable to dataset versions and retrieval context.
Query, transform, materialize, and profile on DuckDB + Parquet — inside a tenant + namespace boundary.
How to pass audits without screenshots: deterministic artifacts, reproducible history, and predictable resolution.
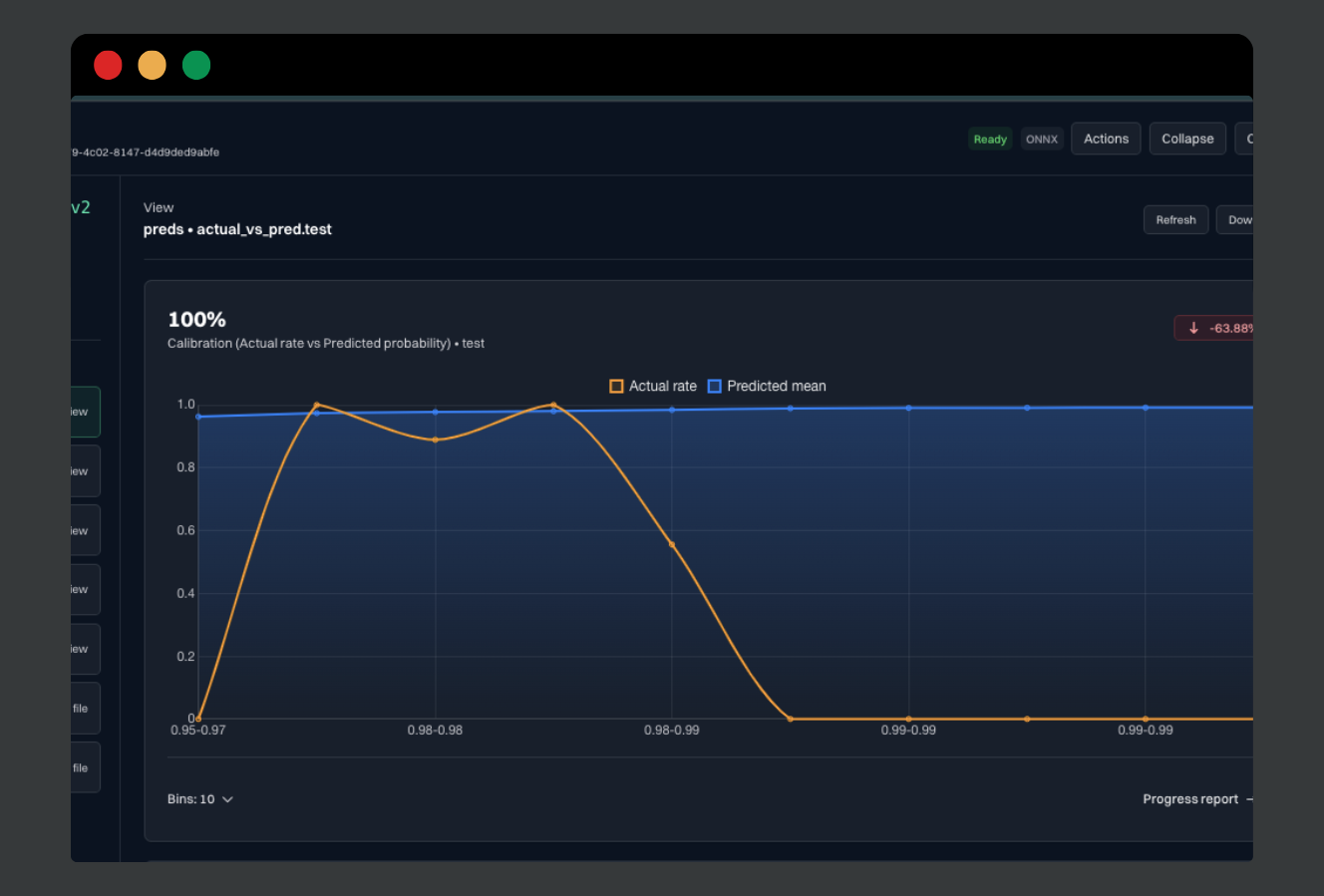
If your system needs to stay explainable months later, you want first-class versions and lineage. If you only need a one-off demo, you’ll feel the “boring constraints” quickly — and that’s the point.
What Xalorra is (and is not)
A control plane for audit-friendly AI workflows.
Xalorra unifies lakehouse ops and versioned ML behind stable HTTP contracts. RAG is gateway-based (Beta). Xalorra does not host foundation models.
Solutions are easy to claim.
Shipping them in production is harder. If you want audit-friendly AI workflows, start with the contracts, versions, and lineage.