Use Cases
Start with the outcome you need.
Choose a use case to see the exact shape of the workflow: what’s versioned, what’s traced, what’s enforced, and what you can prove later.
Ground answers in your datasets: tenant-safe retrieval context and outputs traceable to dataset scope.
Keep AI workflows enforceable: tenant isolation, namespace boundaries, artifacts, and stable contracts.
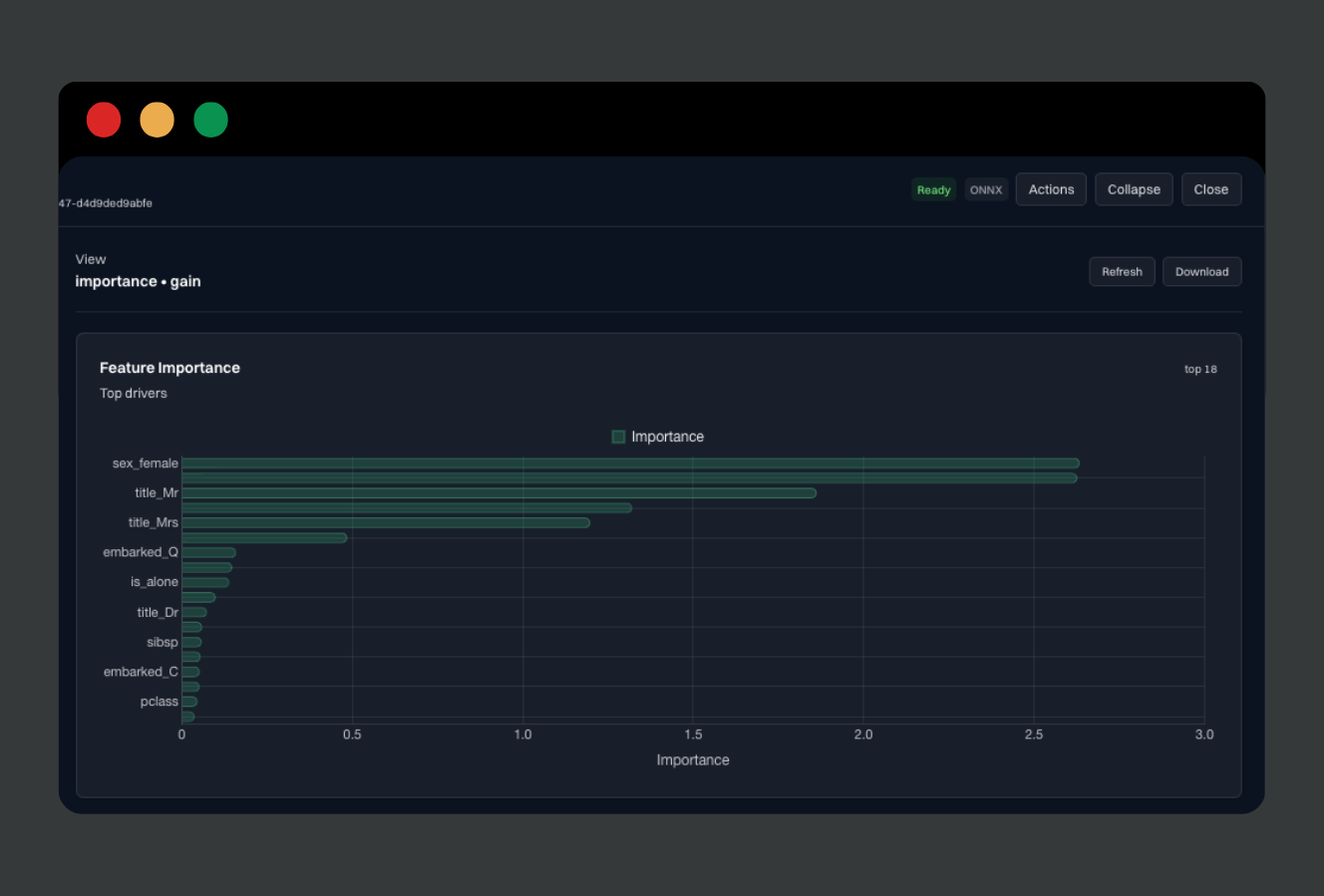
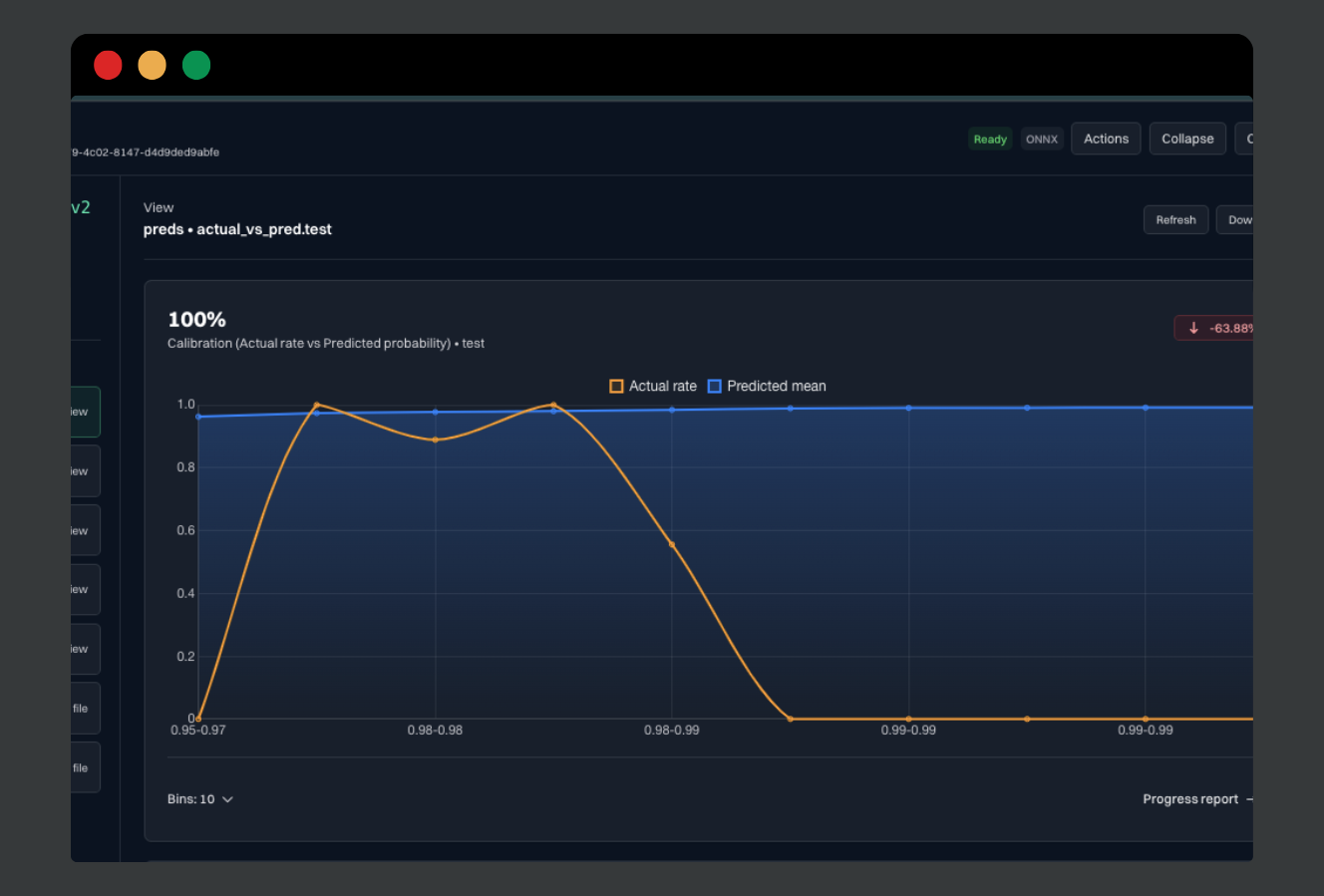
Move from screenshots to reproducible history: deterministic artifacts and predictable resolution rules.
Query/transform/materialize/profile inside a tenant + namespace boundary on DuckDB + Parquet.
A use case here isn’t a marketing slogan. It’s a reproducible flow: scoped inputs, controlled writes, predictable artifacts, and traceable history across runs. If any of that sounds “too strict,” you’re probably building a demo — not production.
The foundation beneath every use case
Tenant isolation, versioning, lineage — behind stable HTTP contracts.
Use cases differ, but the mechanics stay consistent: scoped data, versioned outputs, traceable runs, and predictable artifacts. RAG is gateway-based (Beta). Xalorra does not host foundation models.
Pick a use case.
Then prove it.
If your stakeholders ask “how do we know?”, you want versioned artifacts and lineage. That’s the baseline here.